One of my favorite aspects of VFX is compositing CG, especially doing vector math and tricks with tech passes to finish off a shot. Often when I’m working with a compositing team, I find myself wishing we could do the same tricks on the plate as we can with the CG elements, like just break out the point world and normals and start relighting. A couple plug-ins kind of help with stuff this, and if LIDAR or photo modeling is provided you can always find ways to generate this data, but with modern technology shouldn’t we be able to extract this data right from the image a bit easier? To find out how plausible this could be, I decided to put together another little experiment with deep learning and see what I could come up with.
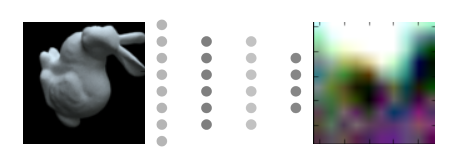
To extract all passes at once might be too dangerously large of a goal to start with, so I decided to narrow down my focus to just getting the beauty pass to convert to a normals pass. In theory, this experiment could be set up almost the same as the previous HDRI experiment, just generate a bunch of images pairs out of Maya as my training data, and throw them at my network as an X and Y pair. With a bit of concern that extracting normals might need harder training data, I decided to spend some time improving my random scene generator, this time I added the ability to randomly assign textures for diffuse, metalness and specular glossiness; which hopefully would give it a broader range of things it could try to learn.

Not being sure exactly which architecture to use for this problem, I read a bunch of recent papers on computer vision and eventually decided maybe a pix2pix network could do this type of image to image translation, you can read the detailed description of how this works in the paper “Image to Image Translation with Conditional Adversarial Networks”.
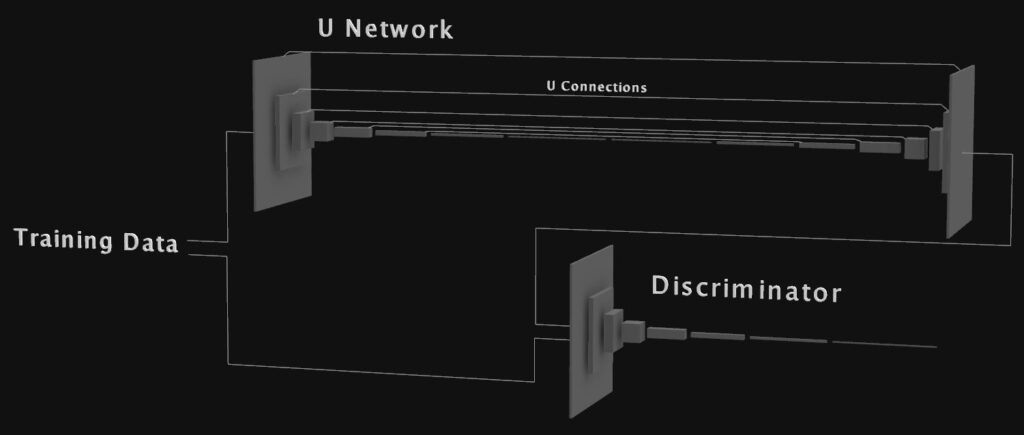
After I got the network built I ran some tests on the first couple thousand samples my script had generated, the results, well they were not what I expected. They looked pretty and all, but instead of being something that looked technically accurate, they were more like an artist’s rendition of what the scene would like if it melted a lot first and then was converted to normals. After a couple days of screwing around changing things I finally got it to the point where non-melted images were being generated, although the network might not exactly be pix2pix anymore, it’s for sure a close cousin.
Eventually, my samples finished being generated, and I started training the model on the full training set, plus a bunch of additional augmented images generated from it. It took about a day to reach a point where no matter what hyper-parameter was changed the model wasn’t improving much, so I decided to just see what I’ve ended up with. You can see here the model’s predictions on the test set came out a bit fluffy, however with enough form that it still appears to have learned something…

Nearing the end of the training process, I used a photo to monitor how well the network was generalizing outside of the validation set, here is a little GIF I made from of every 10th batch:

To test out the original idea behind this whole thing, here are some predictions generated from some photos and another painting (also the same image from above):
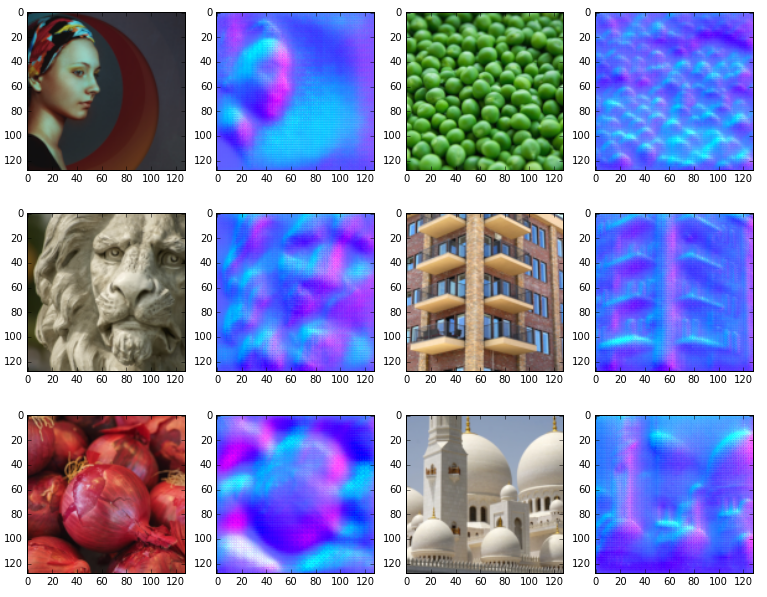
Now, these results are also a bit fluffy, and it appears that buildings don’t work quite as well as the more organic looking samples (A couple images failed outright). However, with this proof of concept functioning on a basic level, I think it’s reasonable to say that investing more time in this idea could yield a viable tool. And of course, tools out there like crazybump will get better with each release, but it’s still exciting to see what ideas can be shoved into a neural net!
-NeuralVFX